

Firebase is a backend-as-service (Bass) platform for creating mobile and web applications. In this section, we will learn to build serverless web apps, import data into a serverless database, and build a Google Assistant application with Firebase and its Google Cloud integrations.
In this section, we will read through a fictitious business scenario and assist the characters with their serverless migration plan.
Twelve years ago, Lily started the Pet Theory chain of veterinary clinics. The Pet Theory chain has expanded rapidly over the last few years. However, their old appointment scheduling system is not able to handle the increased load, so Lily is asking we will build a cloud-based system that scales better than the legacy solution.
Pet Theory’s Ops team is a single person, Patrick, so they need a solution that doesn’t require lots of ongoing maintenance. The team has decided to go with serverless technology.
Ruby has been hired as a consultant to help Pet Theory make the transition to serverless. After comparing serverless database options, the team decides to go with Cloud Firestore. Since Firestore is serverless, capacity doesn’t have to be provisioned ahead of time which means that there is no risk of running into storage or operations limits. Firestore keeps our data in-sync across client apps through realtime listeners and offers offline support for mobile and web, so a responsive app can be built that works regardless of network latency or Internet connectivity.
In this lab, we will help Patrick upload Pet Theory’s existing data to a Cloud Firestore database. He will work closely with Ruby to accomplish this.
Architecture
This diagram gives us an overview of the services we will be using and how they connect to one another:
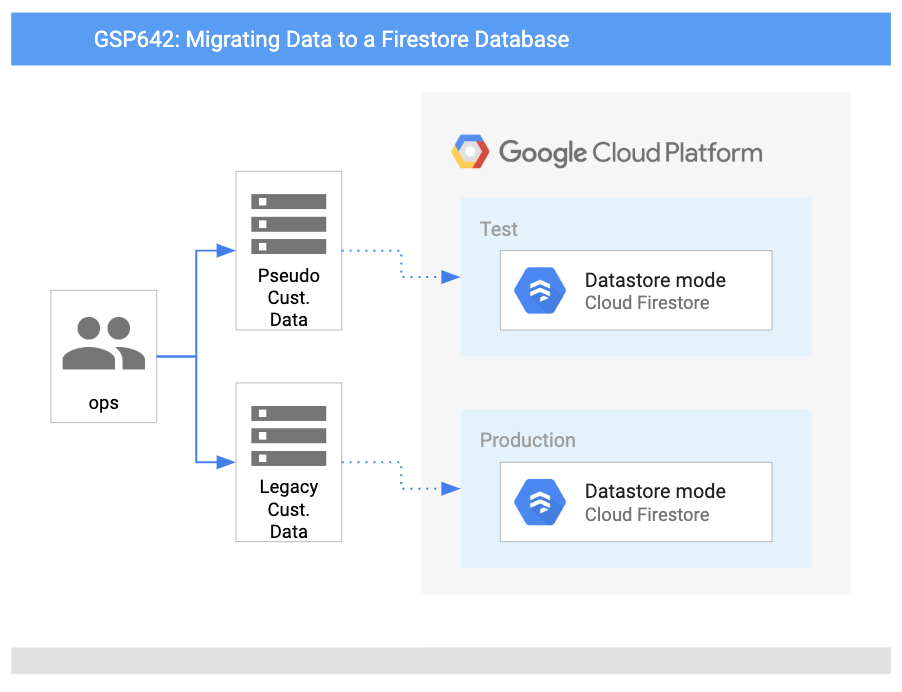
Here we will check:
- Set up Firestore in GCP.
- Write database import code.
- Generate a collection of customer data for testing.
- Import the test customer data into Firestore.
- Manipulate data in Firestore through the Console.
- Add a developer to a GCP project without giving them Firestore access.
Prerequisites
This is a fundamental level lab. This assumes familiarity with the GCP Console and shell environments. Experience with Firebase will be helpful but is not required.
Once we are ready, scroll down and follow the steps below to set up our lab environment.
Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to our Google Cloud resources.
In the Google Cloud Console, go to the Navigation menu and select Firestore
- Click the Select Native Mode button.
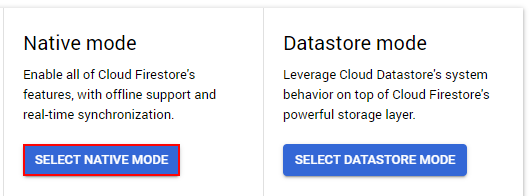
Both modes are high performing with strong consistency, but they look different and are optimized for different use cases.
- Native Mode is good for getting lots of users to access the same data at the same time (plus, it has features like real-time updates and a direct connection between our database and a web/mobile client
- Datastore Mode puts an emphasis on high throughput (lots of reads and writes).
In the Select, a location dropdown, choose a database region closest to our location and then click Create Database.
- In Cloud Shell, run the following command to clone the Pet Theory repository:
git clone https://github.com/rosera/pet-theory- Use the Cloud Shell Code Editor (or our preferred editor) to edit our files. From the top ribbon of your Cloud Shell session, click on the Open in new window icon, it will open a new tab. Then click Open Editor:

- Then change our current working directory to
lab01:
cd pet-theory/lab01content_copyIn the directory, we can see Patrick’s package.json. This file lists the packages that our Node.js project depends on and makes your build reproducible, and therefore easier to share with others.
- Run the following command to do so:
npm install @google-cloud/firestorecontent_copy- To enable the app to write logs to Stackdriver Logging, install an additional module:
npm install @google-cloud/logging
const {promisify} = require('util');
const parse = promisify(require('csv-parse'));
const {readFile} = require('fs').promises;
if (process.argv.length < 3) {
console.error('Please include a path to a csv file');
process.exit(1);
}
function writeToDatabase(records) {
records.forEach((record, i) => {
console.log(`ID: ${record.id} Email: ${record.email} Name: ${record.name} Phone: ${record.phone}`);
});
return ;
}
async function importCsv(csvFileName) {
const fileContents = await readFile(csvFileName, 'utf8');
const records = await parse(fileContents, { columns: true });
try {
await writeToDatabase(records);
}
catch (e) {
console.error(e);
process.exit(1);
}
console.log(`Wrote ${records.length} records`);
}
importCsv(process.argv[2]).catch(e => console.error(e));It takes the output from the input CSV file and imports it into the legacy database. Next, update this code to write to Firestore.
- Open the file
pet-theory/lab01/importTestData.js.
To reference the Firestore API via the application, we need to add the peer dependency to the existing codebase.
- Add the following Firestore dependency on line 4 of the file:
- Add the following Firestore dependency on line 4 of the file:
const {Firestore} = require('@google-cloud/firestore');
content_copyEnsure that our code looks like the following:
const {promisify} = require('util');
const parse = promisify(require('csv-parse'));
const {readFile} = require('fs').promises;
const {Firestore} = require('@google-cloud/firestore'); // add thisAdd the following code underneath line 9, or the if (process.argv.length < 3) conditional:
const db = new Firestore();
function writeToFirestore(records) {
const batchCommits = [];
let batch = db.batch();
records.forEach((record, i) => {
var docRef = db.collection('customers').doc(record.email);
batch.set(docRef, record);
if ((i + 1) % 500 === 0) {
console.log(`Writing record ${i + 1}`);
batchCommits.push(batch.commit());
batch = db.batch();
}
});
batchCommits.push(batch.commit());
return Promise.all(batchCommits);
}The above code snippet declares a new database object, which references the database created earlier in the lab. The function uses a batch process in which each of the records is processed in turn and sets a document reference based on the identifier added. At the end of the function, the batch content is written to the database.
Finally, we need to add a call to the new function. Update the importCsv function to add the function call to writeToFirestore and remove the call to writeToDatabase. It should look like this:
async function importCsv(csvFileName) {
const fileContents = await readFile(csvFileName, 'utf8');
const records = await parse(fileContents, { columns: true });
try {
await writeToFirestore(records);
// await writeToDatabase(records);
}
catch (e) {
console.error(e);
process.exit(1);
}
console.log(`Wrote ${records.length} records`);
}Next, add logging for the application. To reference the Logging API via the application, add the peer dependency to the existing codebase. Add the line const {Logging} = require('@google-cloud/logging'); just below the other required statements at the top of the file:
Add a few constant variables and initialize the Logging client. Add those just below the above lines in the file (~line 5), like this:
const logName = 'pet-theory-logs-importTestData';
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
type: 'global',
};async function importCsv(csvFileName) {
const fileContents = await readFile(csvFileName, 'utf8');
const records = await parse(fileContents, { columns: true });
try {
await writeToFirestore(records);
//await writeToDatabase(records);
}
catch (e) {
console.error(e);
process.exit(1);
}
console.log(`Wrote ${records.length} records`);
// A text log entry
success_message = `Success: importTestData - Wrote ${records.length} records`
const entry = log.entry({resource: resource}, {message: `${success_message}`});
log.write([entry]);
}Now when the application code is run, the Firestore database will be updated with the contents of the CSV file. The function importCsv takes a filename and parses the content on a line-by-line basis. Each line processed is now sent to the Firestore function writeToFirestore, where each new record is written to the “customer” database.
Add Logging for the codebase. Reference the Logging API module from the application code with the following:
const fs = require('fs');
const faker = require('faker');
const {Logging} = require('@google-cloud/logging'); //add thisNow add a few constant variables and initialize the Logging client. Add those just below the const statements:
const logName = 'pet-theory-logs-createTestData';
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
// This example targets the "global" resource for simplicity
type: 'global',
};After generating a collection of customer data for testing, we ran a script that imported the data into Firestore. We then learned how to manipulate data in Firestore through the GCP Console.